Индекс ппд 1с что это
1С 8.3 Что означает те или иные регламентные задания (описание видов регламентных заданий)
 – Загрузка классификатора банков Это регламентное задание осуществляет загрузку классификатора банков РФ с сайта РБК. Его регулярная работа поддерживает этот классификатор в актуальном состоянии. И когда мы добавляем очередной расчетный счет – больше шансов, что банк в котором он открыт будет найден нами в классификаторе по БИК.
– Загрузка классификатора банков Это регламентное задание осуществляет загрузку классификатора банков РФ с сайта РБК. Его регулярная работа поддерживает этот классификатор в актуальном состоянии. И когда мы добавляем очередной расчетный счет – больше шансов, что банк в котором он открыт будет найден нами в классификаторе по БИК.
– Загрузка курсов валют
Это регламентное задание загружает курсы валют на текущую дату. Если в программе ведутся валютные операции, то имеет смысл оставить это задание включенным, чтобы не нужно было каждый раз запускать загрузку курсов валют вручную.
– Заполнение данных для ограничения доступа
Это регламентное задание выполняет последовательное заполнение и обновление данных, необходимых для работы подсистемы “Управления доступом” в режиме ограничения доступа на уровне записей.
При включенном режиме ограничения доступа на уровне записей заполняет наборы значений доступа. Заполнение выполняется частями при каждом запуске, пока все
наборы значений доступа не будут заполнены.
[wp_ad_camp_3] При отключении режима ограничения доступа на уровне записей наборы значений доступа (заполненные ранее) удаляются при перезаписи объектов, а не все сразу. Независимо от режима ограничения доступа на уровне записей обновляет кэш-реквизиты. После завершения всех обновлений и заполнений отключает использование регламентного задания.
Задание служебное. Не нужно включать его вручную.
– Извлечение текста
Используется для быстрого поиска данных во вложенных файлах, прикрепленных к базе данных. Если используете поиск во вложенных файлах, то оно имеет смысл.
[wp_ad_camp_3] – Обмен сообщениями по учетным записям документооборота
Регламентное задание по автоматическому обмену с контролирующими органами. Используется при сдаче регламентированной отчетности прямо из 1С.
– Обновление агрегатов
Регламентное задание выполняет обновление агрегатов. Что это за зверь такой?
С помощью агрегатов можно значительно ускорить формирование отчетов по регистрам накопления в тех случаях, когда количество записей в регистре составляет сотни тысяч, миллионы и более.
Ключевая фраза здесь «количество записей в регистре составляет сотни тысяч, миллионы и более», то есть для маленьких по объему регистров, включение агрегатов не имеет смысла.
Агрегаты позволяют создать предрассчитанные данные для формирования отчетов на подобие итогов регистров накопления. Последние рассчитываются платформой автоматически (при условии включения использования итогов для регистра) в отличии от агрегатов. Но для чего нужны агрегаты, если подобную задачу выполняют итоги?
Во-первых, итоги рассчитываются в разрезе месяцев и изменить это нельзя, в то время как агрегаты могут рассчитываться в разрезе дня, месяца, квартала, полугодия и года.
Во-вторых, разрезы агрегатов могут быть произвольными (любой состав измерений регистра накопления), в отличии от итогов, которые рассчитываются по полному составу регистра.
– Обновление данных монитора руководителя
Регламентное задание вызывает обновление данных регистра сведений “ДанныеМонитораРуководителя” по всем организациям. Если монитор руководителя реально используется – задание имеет смысл.
– Обновление задач бухгалтера
Регламентное задание производит обновление и заполнение задач бухгалтера (даты сдачи различных деклараций, отчетов и тому подобное).
– Обновление индекса ППД
Обновляет индекс полнотекстового поиска. Если пользуетесь полнотекстовым поиском – задание имеет смысл. Включается автоматически, если в настройках базы включён полнотекстовый поиск.
– Обновление информации о направлениях сдачи отчетности
Речь идёт об направлениях: в ФСС, в ФНС, в ПФР. Короче, что-то связанное опять же со сдачей электронной отчетности из 1С.
– Обработка заявлений абонентов на подключение электронной подписи в модели сервиса
Какое-то служебное задание, обрабатывающее вашу заявку на подключение электронной подписи, если вы используете 1С в модели сервиса. В общем его точно не следует включать самостоятельно.
– Отложенное обновление ИБ
Задание управляет процессом выполнения отложенных обработчиков обновления. Не следует включать самостоятельно.
– Отправка отчетности абонентов
Отправка регламентированной отчетности абонентов сервиса в контролирующие органы через сервис сдачи отчетности СОС “Калуга-Астрал”. Не следует включать самостоятельно.
– Очистка устаревших версий объектов
Только для служебного использования.
– Перестроение агрегатов
Перестроение агрегатов для оборотных регистров накопления. Не следует включать самостоятельно.
– Пересчет текущих значений относительных дат запрета изменения
Выполняет пересчет и обновление текущий значений относительных дат запрета по состоянию на текущую дату сеанса. Не следует включать самостоятельно.
– Планирование извлечения текста в модели сервиса
Определяет перечень областей данных, в которых требуется извлечение текста и планирует для них его выполнение с использованием очереди заданий. Служебное.
– Получение результатов отправки отчетности
Получение результатов отправки отчетности абонентов сервиса в контролирующие органы от сервиса сдачи отчетности СОС “Калуга-Астрал”. Служебное.
– Проверка контрагентов
Для модели сервиса обновляет состояния контрагентов (всё ли у него ОК с реквизитами). Для локального режима обновляет состояния и записывает недостающие ИНН и КПП.
– Слияние индекса ППД
Выполняет слияние индексов полнотекстового поиска. Работа задания связана опять же с полнотекстовым поиском (куда же поиск без индекса).
– Удаление неактуальной информации синхронизации
Выполняет удаление информации синхронизации, которая не была удалена из-за сбоев в работе программы. Удалению подлежат файлы с датой размещения более суток.
– Удаление помеченных объектов программы
Удаляет помеченные объекты из регламентного задания.
– Установка периода рассчитанных итогов
Служебное задание, устанавливающее период рассчитанных итогов. По итоги писалось выше.
zdst.net
Индексы в 1С 8.3 и 8.2
Использование индексов 1С — важнейший момент в оптимизации работы информационной системы 1С. Но они очень часто игнорируются разработчиками.
Ниже я попытаюсь рассказать, что же это такое — индексы 1С 8.3, и как их использовать.
Что же такое индексы в 1С?
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов. Индексы сокращают объем данных, которые необходимо считать, чтобы возвратить результирующий набор.
Получите 267 видеоуроков по 1С бесплатно:
В 1С индексом таблицы является совокупность реквизитов с установленным флагом «индексировать». Но у каждой таблицы есть свои особенности. Например, в индекс у регистра бухгалтерии автоматически попадают поля период и счет. Их рекомендуют использовать для оптимизации работы системы.
Индекс хранится в отдельной таблице БД, где связывает определенные строки таблицы с ключами индексов. Т.е. при поиске не нужно обходить все строки базы данных, а последовательно по ключам отбирать наборы записей и перебирать уже небольшие наборы информации.
Из-за особенностей СУБД каждая из них накладывает свои ограничения на использования индексов:
Ограничения на индексы в файловой базе 1С
В файловой базе единственным ограничением является максимальная длина ключа индекса, которая ограничивается 1920 байтами. При попытке реструктуризации базы данных с ключом большей длины появится ошибка — «Длина ключа индекса превышает максимально допустимую«.
Ограничения на индексы в базе 1С на MS SQL
На MS SQL, согласно документации, к ограничениям по длине индекса добавляется еще и количество ключей индекса, если количество полей будет превышено, индекс просто обрежется:
- количество ключей индекса — максимум 16
- суммарная длина индекса — 900 байт
Рекомендации по оптимизации работы 1С
- не рекомендуется использовать большое количество измерений и субконто в регистрах бухгалтерии;
- в планах счетов в рекомендациях устанавливать не более 4 субконто;
- нежелательно использовать поля составного типа — это сильно понижает скорость работы системы;
- не рекомендуется в измерениях регистров использовать поля с примитивным типом (число, строка и т.п.), если необходимо использовать значения примитивных видов, лучше создайте справочник, где будут указываться данные значения. Например: если Вы используете дату как измерение, лучше создать справочник «Даты», где единственным реквизитом будет реквизит с типом «дата»;
- не индексируйте строковые поля большой длины — это уменьшает быстродействие системы.
К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области.
Остались вопросы? СПРОСИТЕ в комментариях!
programmist1s.ru
ВЛИЯНИЕ ИНДЕКСОВ НА ПРОИЗВОДИТЕЛЬНОСТЬ 1С:ПРЕДПРИЯТИЕ 8
— Ну у вас и запросы! — сказала база данных и повисла…
Краткий ответ на вопрос заголовка заключается в том, что это позволит выполнять запросы быстро и уменьшать негативное влияние блокировок на производительность в многопользовательском режиме.
Что такое индекс?
Подобно содержанию в книге, индекс в базе данных позволяет быстро искать конкретные сведения в таблице.
Сначала поговорим про индексы в MS SQL Server. Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов. Индекс содержит ключи, построенные из одного или нескольких столбцов таблицы или представления, и указатели, которые сопоставляются с местом хранения заданных данных.
Индексы сокращают объем данных, которые необходимо считать, чтобы возвратить результирующий набор.
Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.
Просто объекта «Индекс» в платформе 1С:Предприятие 8 нет.
Индексы таблиц в базе данных 1С:Предприятие создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации.
- Неявным образом индексы создаются с учетом типов полей ключа данных — набора полей, однозначно определяющих данные. Для объектных типов данных (Справочник, Документ, ПланСчетов и др.) — это «Ссылка»; для регистров, подчиненных регистратору (РегистрНакопления, РегистрБухгалтерии, РегистрСведений, подчиненный регистратору и др.) — «Регистратор»; для регистров сведений, неподчиненных регистратору — поля, соответствующие изменениям, входящим в основной отбор регистра; для констант — идентификатор объекта метаданных Константы.
- индексируются данные в «соответствии»
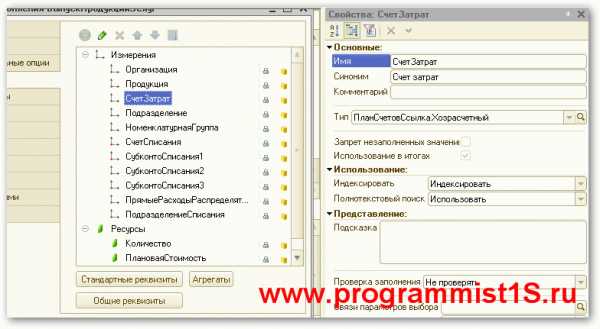
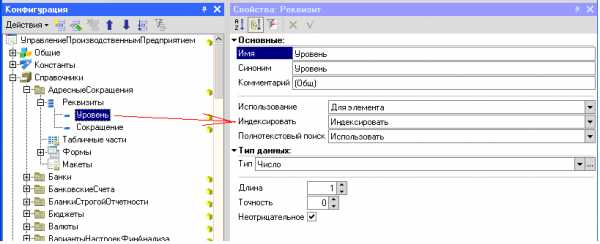
Явным способом включением свойства «Индексировать» реквизитов и измерений с значение «Индексировать» и «Индексировать с доп. Упорядочиванием». Вариант ««Индексировать с доп. Упорядочиванием»» включает обычно колонку «код» или «наименование» в индекс.
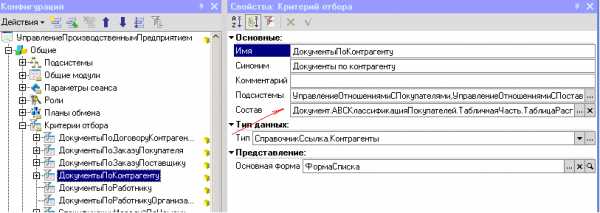
Еще одним явным способом можно считать добавление объекта метаданных в объект метаданных «критерий отбора».
Можно указать индекс для таблицы значений и в запросах для временных таблиц.
ВЫБРАТЬ Код, Наименование ПОМЕСТИТЬ ВременнаяТаблица ИЗ Справочник.Номенклатура
ИНДЕКСИРОВАТЬ ПО Код
В любом случае, надо понимать, что говоря об индексах, мы фактически подразумеваем индексы СУБД, которая используется для 1С:Предприятие. Исключению составляют объекты типа Таблица значений, когда индексы находятся в RAM (оперативной памяти).
Физическая сущность индексов в MS SQL Server.
Физически данные хранятся на 8Кб страницах. Сразу после создания, пока таблица не имеет индексов, таблица выглядит как куча (heap) данных. Записи не имеют определенного порядка хранения. Когда вы хотите получить доступ к данным, SQL Server будет производить сканирование таблицы (table scan). SQL Server сканирует всю таблицу, что бы найти искомые записи. Отсюда становятся понятными базовые функции индексов: — увеличение скорости доступа к данным,
— поддержка уникальности данных.
Несмотря на достоинства, индексы так же имеют и ряд недостатков. Первый из них – индексы занимают дополнительное место на диске и в оперативной памяти. Каждый раз когда вы создаете индекс, вы сохраняете ключи в порядке убывания или возрастания, которые могут иметь многоуровневую структуру. И чем больше/длиннее ключ, тем больше размер индекса. Второй недостаток – замедляются операции вставки, обновления и удаления записей. В среде MS SQL Server реализовано несколько типов индексов:
- некластерные индексы;
- кластерные (или кластеризованные) индексы;
- уникальные индексы;
- индексы с включенными столбцами
- индексированные представления
- полнотекстовый
- XML
Некластерный индекс
Некластерные индексы – не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки. Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
- информацию об идентификационном номере файла, в котором хранится строка;
- идентификационный номер страницы соответствующих данных;
- номер искомой строки на соответствующей странице;
- содержимое столбца.
Некластерных индексов может быть несколько для одной таблицы.
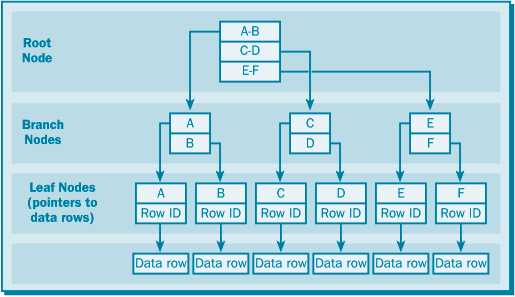
Некластеризованный индекс по таблице, не имеющей кластеризованного индекса
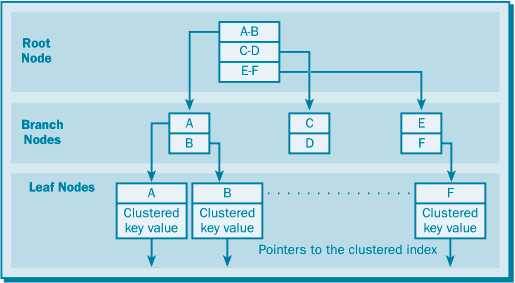
Некластеризованный индекс по таблице, имеющей кластеризованный индекс
Кластерный (кластеризованный) индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту. Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице. Естественно, в таблице может быть определен только один кластерный индекс. Кластерный индекс может включать несколько столбцов. Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс. При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
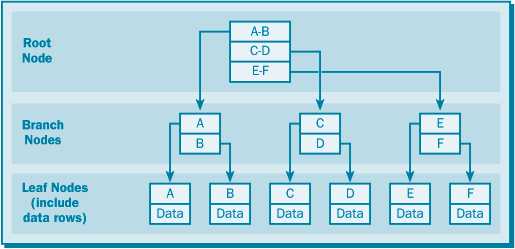
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения. Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
1С:Предприятие 8 активно использует кластерные уникальные индексы. Это означает, что можно получить ошибку не уникального индекса.
Если не уникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000. «Рыба» скрипта для определения не уникальных записей: SELECT COUNT(*) Counter, from GROUP BY
HAVING Counter > 1
Понятие первичного и внешнего ключа
Первичный ключ (primary key) – это набор столбцов таблицы, значения которых уникально определяют строку.
Внешний ключ (foreign key) . Внешним ключом называется поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами. Внешний ключ в таблице может ссылаться и на саму эту таблицу. Такие внешние ключи, в основном, используются для хранения древовидной структуры данных в реляционной таблице. СУБД поддерживают автоматический контроль ссылочной целостности на внешних ключах. 1С не использует внешние ключи. Ссылочная целостность обеспечивается логикой приложения.
Ограничения индексов
Индекс может быть создан на основании нескольких полей. В этом случае существует ограничение – длина ключа индекса не должна превышать 900 байтов и не более 16 ключевых столбцов. На практике это означает что при создании индекса, включающего более 16 полей, индекс усекается. Это может оказать влияние на производительность при количестве субконто составного типа более 4х.
В актуальных релизах платформы выполнена оптимизация данного случая и используется хэш по ключу полей, но это медленней «полноценных» индексов.
Статистика индексов
Microsoft SQL Server собирает статистику по индексам и полям данных, хранимых в базе. Эта статистика используется оптимизатором запроса SQL Server при выборе оптимального плана исполнения запросов на выборку или обновление данных.
При создании индекса оптимизатор запросов автоматически сохраняет данные статистики о проиндексированых столбцах.
Просмотр статистики — sp_helpstats.
Фрагментация индексов
Чрезмерная фрагментация создает проблемы для больших операций ввода-вывода. Фрагментация не должна превышать 25%. От снижения фрагментации индексов могут выиграть операции сканирования больших диапазонов данных. Для этого рекомендуется выполнять периодическую дефрагментацию индексов. Обратите внимание, что при дефрагментации индексов (по умолчанию) автоматически обновляется статистика. Смотреть степень фрагментированности индексов можно штатными средствами СУБД или в разрезе объектов метаданных можно например с помощью бесплатного онлайн-сервиса http://www.gilev.ru/sqlsize/
Оптимизация размещения индексов
При объеме таблиц не позволяющем им «разместиться» в оперативной памяти сервера, на первое место выходит скорость дисковой подсистемы (I/O). И здесь можно обратить внимание возможность размещать индексы в отдельных файлах расположенных на разных жестких дисках.
Подробное описание действий http://technet.microsoft.com/ru-ru/library/ms175905.aspx Использование индекса из другой файловой группы повышает производительность некластерных индексов в связи с параллельностью выполнения процессов ввода/вывода и работы с самим индексом.
Для определения размеров можно использовать выше упомянутую обработку.
Влияние индексов на блокировки
Отсутствие необходимого индекса для запроса означает перебор всех записей таблицы, что в свою очередь приводит к избыточным блокировкам, т.е. блокируются лишние записи. Кроме того, чем дольше выполняется запрос из-за отсутствующих индексов, тем больше время удержания блокировок. Другая причина блокировок — малое количество записей в таблицах. В связи с этим SQL Server, при выборе плана выполнения запроса, не использует индексы, а обходит всю таблицу(Table Scan), блокируя целиком. Для того, чтобы избежать подобных блокировок, необходимо увеличить количество записей в таблицах до 1500-2000. В этом случае сканирование таблицы становится долее дорогостоящей операцией и SQL Server начинает использовать индексы. Конечно это можно сделать не всегда, ряд справочников как «Организации», «Склады», «Подразделения» и т.п. обычно имеют мало записей. В этих случаях индексирование не будет улучшать работу.
Эффективность индексов
Мы уже отметили в заголовке статьи, что нас интересуют влияние индексов на быстродействие запросов. Итак, индексы наиболее подходят для задач следующего типа:
- Запросы, которые указывают «узкие» критерии поиска. Такие запросы должны считывать лишь небольшое число строк, отвечающих определенным критериям.
- Запросы, которые указывают диапазон значений. Эти запросы также должны считывать небольшое количество строк.
- Поиск, который используется в операциях связывания. Колонки, которые часто используются как ключи связывания, прекрасно подходят для индексов.
- Поиск, при котором данные считываются в определенном порядке. Если результирующий набор данных должен быть отсортирован в порядке кластеризованного индекса, то сортировка не нужна, поскольку результирующий набор данных уже заранее отсортирован. Например, если кластеризованный индекс создан по колонкам lastname (фамилия), firstname (имя), а для приложения требуется сортировка по фамилии и затем по имени, то здесь нет необходимости добавлять инструкцию ORDER BY.
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов. И наоборот, неиспользуемые (редко используемые) индексы скорее ухудшают скорость записи данных (поскольку каждая операция, изменяющая данные, должна также обновлять страницы индексов) и создают избыточный объем базы.
Покрывающим (для данного запроса), называется индекс в котором есть все необходимые поля для этого запроса. Например, если индекс создан по колонкам a, b и c, а оператор SELECT запрашивает данные только из этих колонок, то требуется доступ только к индексу.
Для того, что бы определить эффективность индекса, мы можем приблизительно оценить с помощью бесплатного онлайн-сервиса http://www.gilev.ru/querytj/ показывающий «план исполнения запроса» и используемые индексы.
www.gilev.ru
Два простых способа увеличить скорость работы «1С:Бухгалтерия предприятия ред. 3.0»
25.05.2015 - Просмотров: 7063
Очень часто пользователи, которые обновили 1С:Бухгалтерию редакцию 2.0 на 3.0 жалуются на заметное снижение скорости работы программы. В этой статье мы рассмотрим два простых способа (для файлового варианта базы данных), с помощью которых можно заметно увеличить время отклика программы на действия пользователя.
Первый способ заключается в том, чтобы отключить в 1С:Бухгалтерии механизм «Полнотекстового поиска». При включенном режиме «Полнотекстового поиска» программа в фоновом режиме анализирует все введенную информацию и формирует массив данных данных (так называемый “индекс”) который в дальнейшем используется для ускорения поиска.
Для отключения «Полнотекстового поиска» необходимо включить отображение опции “Все функции”.
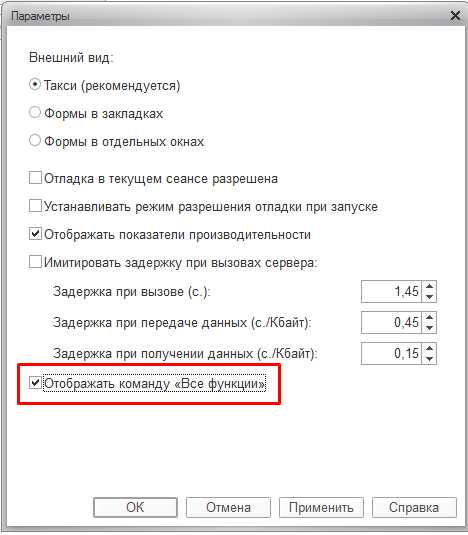
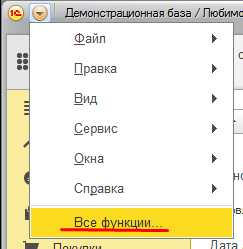
Далее необходимо перейти в “Управление полнотекстовым поиском” и отключить его.
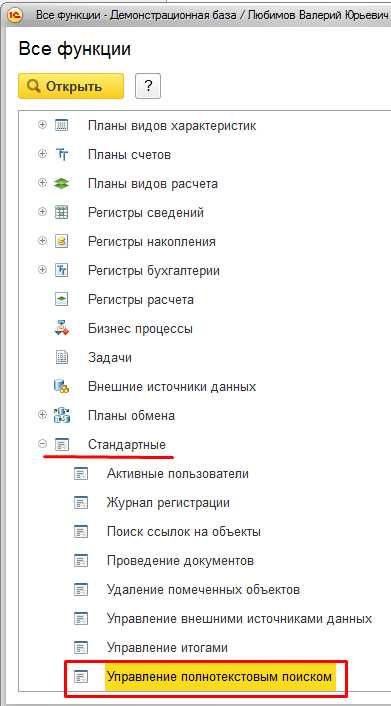
Вторя потенциальная возможность для увеличения быстродействия программы это отключение фоновых и регламентных заданий. Функционал фоновых и регламентных заданий очень полезен когда работает в не рабочее время (например в ночное время). Однако в файловом варианте фоновые и регламентные задания запускаются во время работы пользователя, что приводит к существенному замедлению скорости работы программы.
Варианты решения либо отключить все регламентные задания либо изменить их расписание работы так, чтобы выполнение не пересекалось с рабочим временем.
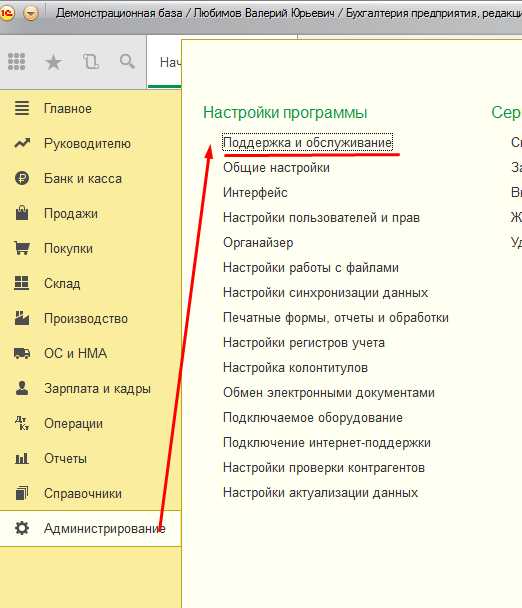
Переход к настройке регламентных и фоновых заданий.
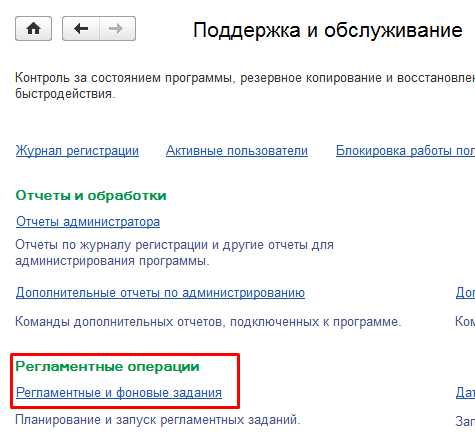
Для отключения регламентного задания необходимо двойным кликом
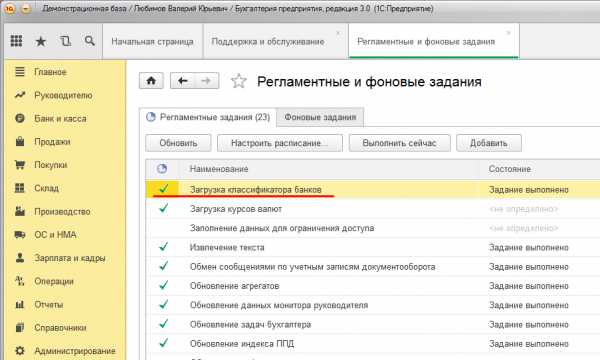
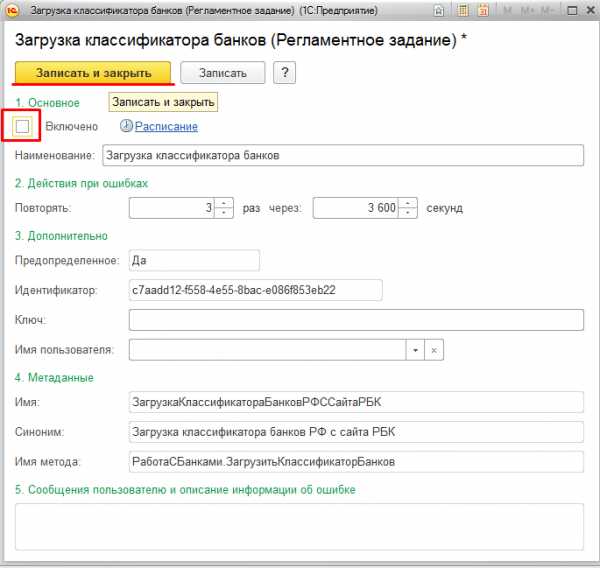
открыть настройки, убрать опцию “Включено” и нажать кнопку “Записать и закрыть”
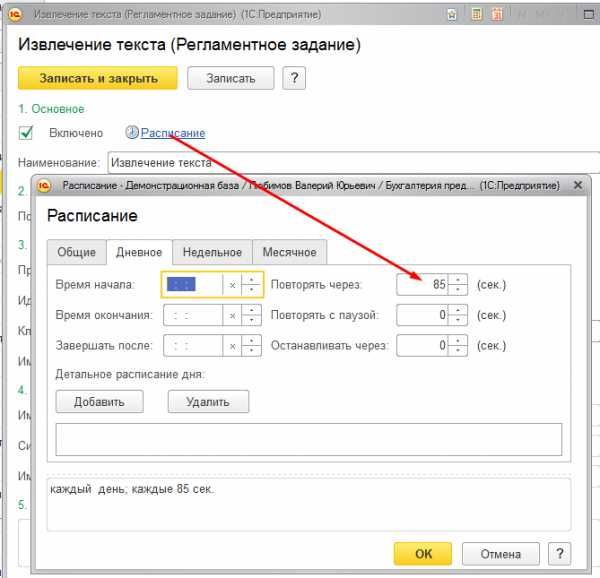
Для настройки расписания работы регламентного задания необходимо перейти по ссылке “Расписание” и выполнить соответствующие настройки.
it-terminal.ru